Deep VQA based on a Novel Hybrid Training Methodology
University of Bristol
![]()


About
In recent years, deep learning techniques have been widely applied to video quality assessment (VQA), showing significant potential to achieve higher correlation performance with subjective opinions compared to conventional approaches. However, these methods are often developed based on limited training materials and evaluated through cross validation, due to the lack of large scale subjective databases. In this context, this paper proposes a new hybrid training methodology, which generates large volumes of training data by using quality indices from an existing perceptual quality metric, VMAF, as training targets, instead of actual subjective opinion scores. An additional shallow CNN is also employed for temporal pooling, which was trained based on a small subjective video database. The resulting Deep Video Quality Metric (based on Hybrid Training), DVQM-HT, has been fully tested on eight HD subjective video databases, and consistently exhibits higher correlation with perceptual quality compared to other deep quality assessment methods, with an average SROCC value of 0.8263.
Source code
Source code from github will be avaliable very soon.Model
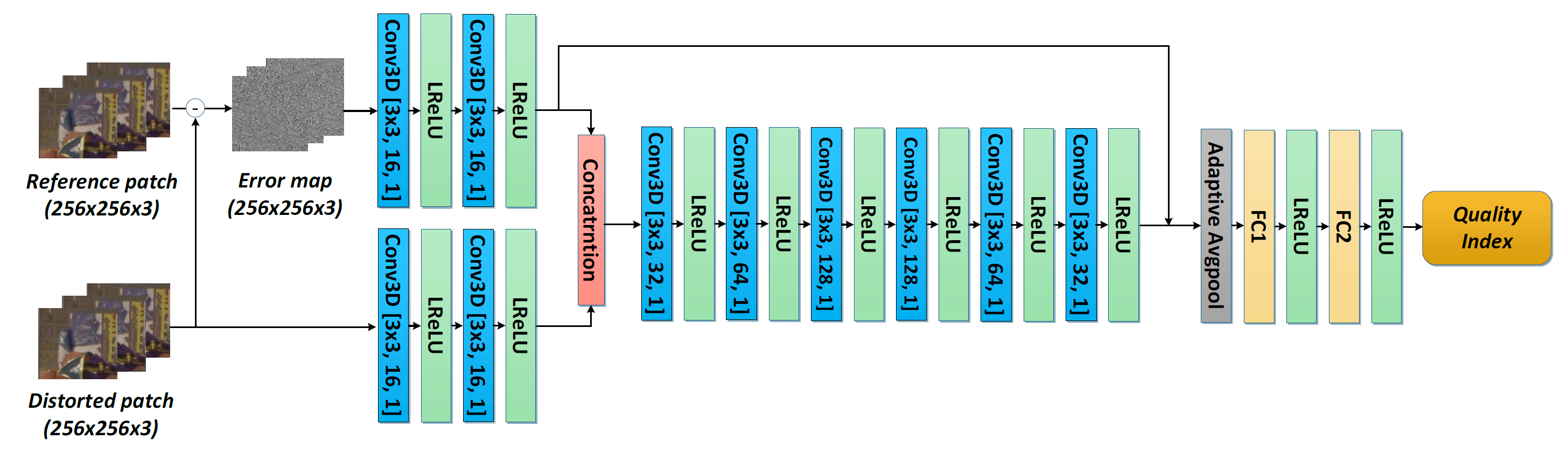
Results
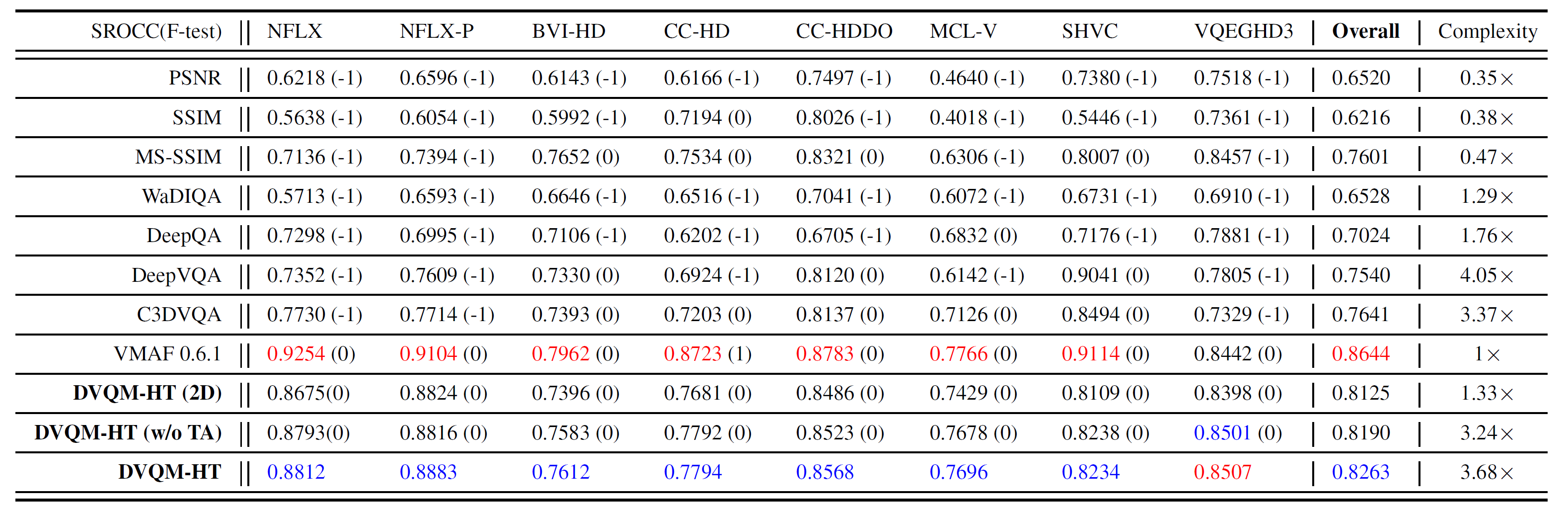
Performance of the proposed method and other benchmark approaches on eight test databases. The values in each cell x(y) correspond to the SROCC value (x) and F-test result (y) at 95% confidence interval. y=1 suggests that the metric is superior to DVQM-HT (y=-1 if the opposite is true), while y=0 indicates that there is no significant difference between them. The figures in color red and blue indicate the highest and second highest SROCC values respectively in each column.
Citation
@misc{feng2022deep,
title={Deep VQA based on a Novel Hybrid Training Methodology},
author={Chen Feng and Fan Zhang and David R. Bull},
year={2022},
eprint={2202.08595},
archivePrefix={arXiv},
primaryClass={eess.IV}
}
}[paper]