RankDVQA-mini: Knowledge Distillation-Driven Deep Video Quality Assessment
University of Bristol
![]()


About
Deep learning-based video quality assessment (deep VQA) has demonstrated significant potential in surpassing conventional metrics, with promising improvement in terms of the correlation with human perception. However, the practical deployment of these CNN-based VQA models is often limited due to their high computational complexity and large memory requirement. To address this issue, we significantly reduce the model size and runtime of one of the state-of-the-art deep VQA methods, RankDVQA, by employing a two-phase workflow that integrates pruning-driven model compression with multi-level knowledge distillation. The resulting lightweight quality metric, RankDVQA-mini, only requires less than 10\% of the model size compared to its full version (9.6% in terms of FLOPs), while still maintaining a superior quality prediction performance to most existing deep VQA methods - only outperformed by the original RankDVQA. The source code of the RankDVQA-mini has been released for public evaluation.
Source code
Source code from github will be avaliable very soon.Model
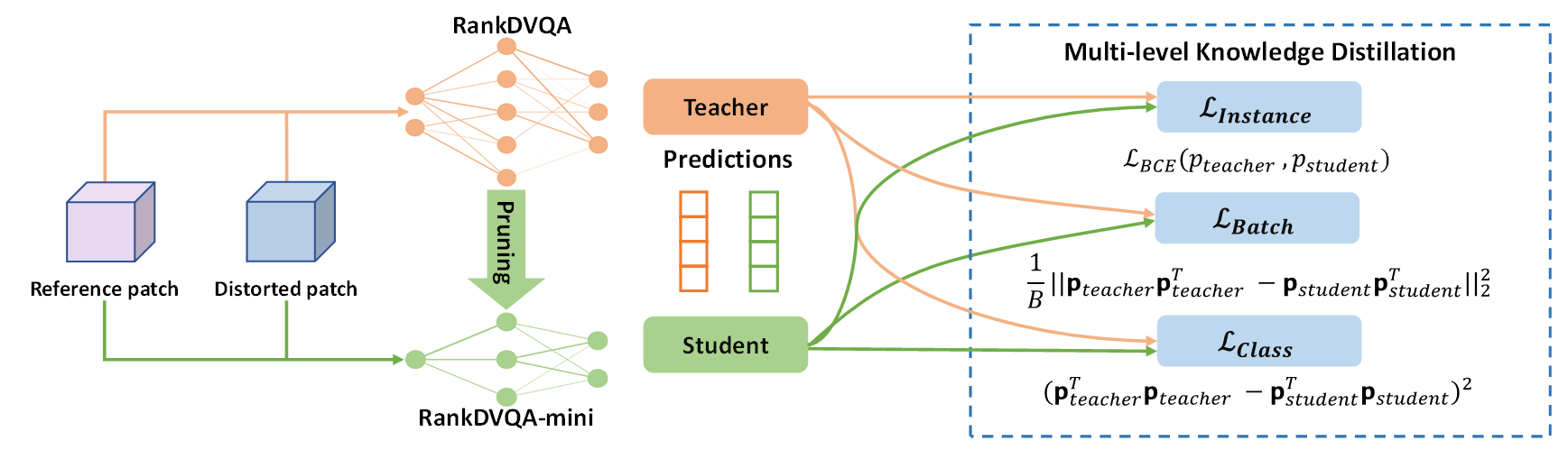
Acknowledgments
Research reported in this paper was supported by an Amazon Research Award, Fall 2022 CFP. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not reflect the views of Amazon. We also appreciate the funding from the China Scholarship Council, University of Bristol, and the UKRI MyWorld Strength in Places Programme (SIPF00006/1).
Citation
@misc{feng2023rankdvqamini,
title={RankDVQA-mini: Knowledge Distillation-Driven Deep Video Quality Assessment},
author={Chen Feng and Duolikun Danier and Haoran Wang and Fan Zhang and David Bull},
year={2023},
eprint={2312.08864},
archivePrefix={arXiv},
primaryClass={eess.IV}}[paper]